( ESNUG 532 Item 2 ) -------------------------------------------- [09/06/13]
From: [ Frank Schirrmeister of Cadence ]
Subject: CDNS says Hogan missed FPGA compile time, Rent's Rule, probing
Hi, John,
Jim Hogan correctly points out in ESNUG 522 #1 that hardware assisted and
software based verification complement each other -- he has a full section
called "Emulation and SW Simulation Complement Each Other". Two points in
that section need clarification -- compile time and probing in FPGAs.
> Emulator compile time is the total time to prep a job for execution on
> your emulation system, including synthesis and routing. For FPGA-based
> emulators, compilation time is determined by the FPGA routing tools...
>
> - from http://www.deepchip.com/items/0522-03.html
On compile times, Jim also points out that "The one downside to emulation is
it takes a measurable compile time". Well, as I had previously discussed in
ESNUG 517 #6, there are substantial differences between processor-based and
FPGA-based emulation that directly impact the results of compile time and
compile effort.
Routing and partitioning for FPGAs -- regardless of whether it is custom or
commercial -- fundamentally takes much longer. Jim Hogan explains that later
in his article as well -- it is important to consider here, too. According
to the datasheets, Palladium compiles at 35 million gates per hour while
Veloce 2 at up to 40 million gates per hour. What's not mentioned here is
to reach that compile speed, Palladium uses one host, while Veloce and Zebu
need server farms. For comparison, the previous Mentor Veloce datasheet had
specified compile performance at "up to 25 MG/hour (20 CPU)". I am not sure
whether they caught up to Palladium by using more CPUs or whether compile
technology has actually improved.
Why does this matter? To pick a specific example, for a 128 M gate design,
Palladium XP requires a compile time of about 3.2 hours on a quad core host
using 1 of the cores. To get to the same order of magnitude of compile
time, Veloce 2 will use 4.5 hours but needs to use 8 quad core hosts in
parallel, using all the cores.
This makes Palladium XP about 11x more power efficient during compile time.
Veloce is a custom FPGA and can control some routing/debug aspects better
than commercial FPGAs, so a Zebu Server compile for commercial FPGAs would
take even longer and be less power efficient.
So is this likely to change with larger FPGAs? Not really. Rent's Rule
predicts a large FPGA will run out of pins long before all its available
capacity is utilized:
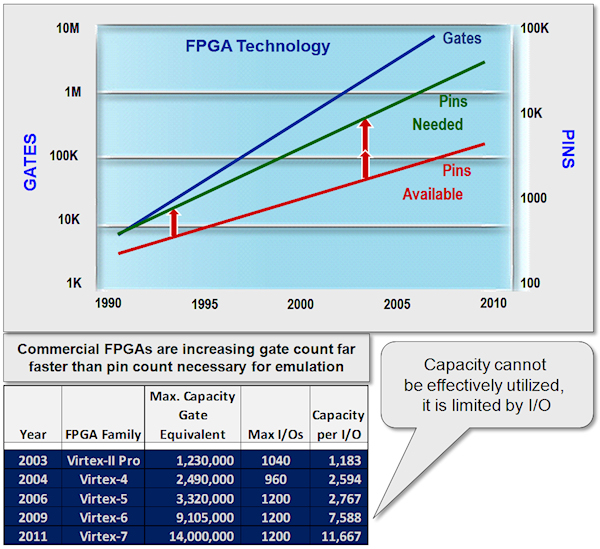 Fig 2: Rent's Rule -- Interconnect between FPGAs gets more difficult
(CLICK ON PIC TO ENLARGE IMAGE.)
FPGA-based emulators need special attention when it comes to partitioning
and routing a design to be mapped into them -- specifically because the FPGA
capacity grows much more quickly than the available bandwidth between them.
Time Division Multiplexing (TDM) of wires seems to be the answer: several
signals share the bandwidth of one wire. The less bandwidth required per
signal, the more signals-per-wire can be used at the same execution speed.
However, in reality, small bandwidth-per-signal is hard to achieve in FPGAs
because route delay unpredictability and timing constraints often increase
compilation time significantly.
Palladium XP does not have these issues -- remember the memory architecture
differences I discussed in Item 1? We eliminated the need for backplanes
and cross bars.
The other point Jim makes is that:
"Increased static and dynamic probing inside today's much bigger
FPGAs has helped emulation grow, too".
Fig 2: Rent's Rule -- Interconnect between FPGAs gets more difficult
(CLICK ON PIC TO ENLARGE IMAGE.)
FPGA-based emulators need special attention when it comes to partitioning
and routing a design to be mapped into them -- specifically because the FPGA
capacity grows much more quickly than the available bandwidth between them.
Time Division Multiplexing (TDM) of wires seems to be the answer: several
signals share the bandwidth of one wire. The less bandwidth required per
signal, the more signals-per-wire can be used at the same execution speed.
However, in reality, small bandwidth-per-signal is hard to achieve in FPGAs
because route delay unpredictability and timing constraints often increase
compilation time significantly.
Palladium XP does not have these issues -- remember the memory architecture
differences I discussed in Item 1? We eliminated the need for backplanes
and cross bars.
The other point Jim makes is that:
"Increased static and dynamic probing inside today's much bigger
FPGAs has helped emulation grow, too".
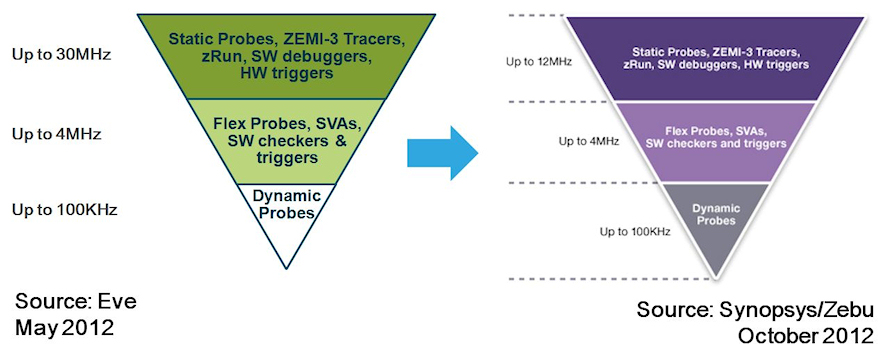 Fig 3: Up to 300X slow down with dynamic probes in FPGAs
(CLICK ON PIC TO ENLARGE IMAGE.)
Yes, probing helps in principle. But adding probes to FPGA-based emulation
immediately causes speed penalties that can be very significant; up to 300X
slower for dynamic probes compared to what processor-based emulation like
Palladium has built in, and up to 7.5x slower for flexible probes (according
to the Zebu Server datasheets).
DeepChip readers have confirmed this probe-caused slow down in ESNUG 486 #1
(Telegent, PLX and Sandforce).
Veloce says it uses integrated trace logic and "at speed hardware" capture.
Palladium had for a long time. We call it "Full Vision". How designers
are actually using this is presented in length in ESNUG 486 #1 as well as
by AMD at CDNLive 2012 [Ref 5].
The key take away from the AMD presentation is the actual debug cycle users
go through. It all boils down to the loop of:
1) design bring-up,
2) execution of test,
3) efficient debug,
4) bug fix, and
5) back to step 1 to confirm that the bug has indeed been removed.
The turnaround time for that cycle matters to users a lot, as also echoed as
one of the responses to Jim's write-up in ESNUG 530 #1:
"The three points we got burned on were Partitioning, Compile
times and Visibility"
So what about Palladium in this area? The AMD presentation is a great
example how the size of your debug window and the speed to upload data from
the emulator to your host for analysis matters a lot. With 1 M cycles,
Palladium had 2.5x the trace buffer size for full vision compared to Veloce,
as well as better upload speed of the collected data to the host. They used
a 128 million gate design as example:
Fig 3: Up to 300X slow down with dynamic probes in FPGAs
(CLICK ON PIC TO ENLARGE IMAGE.)
Yes, probing helps in principle. But adding probes to FPGA-based emulation
immediately causes speed penalties that can be very significant; up to 300X
slower for dynamic probes compared to what processor-based emulation like
Palladium has built in, and up to 7.5x slower for flexible probes (according
to the Zebu Server datasheets).
DeepChip readers have confirmed this probe-caused slow down in ESNUG 486 #1
(Telegent, PLX and Sandforce).
Veloce says it uses integrated trace logic and "at speed hardware" capture.
Palladium had for a long time. We call it "Full Vision". How designers
are actually using this is presented in length in ESNUG 486 #1 as well as
by AMD at CDNLive 2012 [Ref 5].
The key take away from the AMD presentation is the actual debug cycle users
go through. It all boils down to the loop of:
1) design bring-up,
2) execution of test,
3) efficient debug,
4) bug fix, and
5) back to step 1 to confirm that the bug has indeed been removed.
The turnaround time for that cycle matters to users a lot, as also echoed as
one of the responses to Jim's write-up in ESNUG 530 #1:
"The three points we got burned on were Partitioning, Compile
times and Visibility"
So what about Palladium in this area? The AMD presentation is a great
example how the size of your debug window and the speed to upload data from
the emulator to your host for analysis matters a lot. With 1 M cycles,
Palladium had 2.5x the trace buffer size for full vision compared to Veloce,
as well as better upload speed of the collected data to the host. They used
a 128 million gate design as example:
 Fig 4: Impact of Debug Efficiency on Hardware Utilization
(CLICK ON PIC TO ENLARGE IMAGE.)
Why does this matter? To collect the same amount of debug info, Veloce 2
needs to run 2.5 times, while Palladium runs just once. When considering
this together with the 11x less power efficient compile as described above,
Palladium allows users to debug more efficiently and with less power
consumption.
- Frank Schirrmeister
Cadence Design Systems, Inc. San Jose, CA
---- ---- ---- ---- ---- ---- ----
Related Articles
CDNS says Hogan missed granularity, user access, speed, capacity
CDNS says Hogan missed close to 10 emulation customer use models
CDNS says Hogan missed 5 metrics/gotchas for picking an emulator
CDNS says Hogan missed 47 Palladium user papers on Cadence.com
Fig 4: Impact of Debug Efficiency on Hardware Utilization
(CLICK ON PIC TO ENLARGE IMAGE.)
Why does this matter? To collect the same amount of debug info, Veloce 2
needs to run 2.5 times, while Palladium runs just once. When considering
this together with the 11x less power efficient compile as described above,
Palladium allows users to debug more efficiently and with less power
consumption.
- Frank Schirrmeister
Cadence Design Systems, Inc. San Jose, CA
---- ---- ---- ---- ---- ---- ----
Related Articles
CDNS says Hogan missed granularity, user access, speed, capacity
CDNS says Hogan missed close to 10 emulation customer use models
CDNS says Hogan missed 5 metrics/gotchas for picking an emulator
CDNS says Hogan missed 47 Palladium user papers on Cadence.com
Join
Index
Next->Item
|
|









