( ESNUG 571 Item 5 ) -------------------------------------------- [05/19/17]
Subject: Shiv on 10x EDA I/O speed-up with IC Manage PeerCache P2P caching
WAIT!, IT DOES MORE!: In addition, PeerCache also 4X to 20X accelerates
your EDA tool's monster big data "reads" and "writes" with 2000 MB/sec
transfers. Plus, through clever data redundancy reduction (and by only
storing "deltas") it can take 47 TB of design & its related generated
data, and squeeze that down to 200 GB on your hard drive.
- IC Manage PeerCache and CDNS Rocketick get #3 best of at DAC'16
From: [ Shiv Sikand of IC Manage ]
Hi John,
The early customer benchmark data for our PeerCache EDA tool accelerator has
been showing strong speed-up results compared to using NFS v3 as a base.
(details below)
Since we launched PeerCache last DAC (ESNUG 561 #2) there are four main
lessons we've learned from chip design, verification, and CAD teams:
1. Speeding up EDA tools is their #1 priority. Slow data I/O access
due to NFS bottlenecks are dramatically impacting EDA tool speed
for their non-CPU bound jobs and their interactive SW runs.
2. Any speed-up solutions must fit within their existing Network
File System and workflows. Redesigning their NFS is too risky
for production flows. And changing that infrastructure is out of
their charter/authority -- which belongs to IT.
3. Disk space cost is a big deal for both CAD and IT. The majority
are investing in more flash-based devices for their compute farms
to accelerate critical jobs. But this flash storage is not
networked -- making it hard to deploy into the grid. They want to
reduce their expensive Tier 1 filer storage disk space, such as
NetApp and Isilon.
4. Roughly 90% of the data generated is unmanaged, including physical
design and simulation data. Unmanaged data is a source of big
headaches, not only for data transfer bottlenecks, but also for
information accessibility and security.
Let me start by reviewing what PeerCache does at the top level, along with
the results we've seen over the past year since we've been tuning it with
key customers.
---- ---- ---- ---- ---- ---- ----
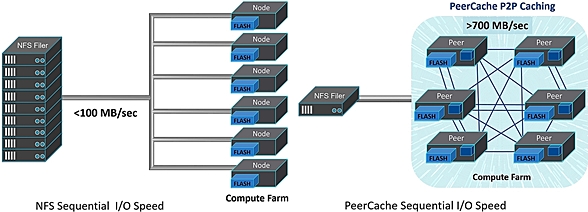
PEER-TO-PEER CACHING GETS YOU 10X EDA TOOL I/O SPEED-UP
Our P2P SW speeds up your EDA tool runs 10x because:
- PeerCache harnesses the inexpensive flash in your existing compute
farm. You can see benefits with as few as 4 compute nodes.
- PeerCache uses flash as cache (rather than direct storage) meaning you
only need small volumes of flash; typically 500 GB to 1 TB per node.
- PeerCache turns your local/scratch flash into one big peer-to-peer
networked flash cache -- all the nodes in the grid can now share the
local data, and it works for both bare metal and virtual machines.
Here's our early customer data using a compute farm with NVMe devices.
PEERCACHE VS. NFS V3
PeerCache
NFS v3 PeerCache Speed Up
------------- -------------- ---------
Sequential
Reads 65,918 KB/sec 707,345 KB/sec >10
Sequential
Writes 75,247 KB/sec 496,376 KB/sec 7
Random I/O 84 seeks/sec 6,787 seeks/sec 81
These elements can easily account for 30% of the overall EDA tool run times.
By creating a P2P network out of your compute node flash devices, PeerCache
effectively gives teams a ~1 GB/sec speed of direct attached storage, as
compared to the much slower sub-100 MB/sec speed of a NAS filer.
PeerCache also allows all files system "stats" to run locally, removing the
central filer CPU bottleneck.
PeerCache will never fully reach local speeds, as the userspace filesystem
and translated metadata translation always adds some overhead -- but we
expect this overhead to be no more than 25 percent.
As you can see, it also reduces filer storage -- which I will cover later
in the Virtual Workspaces section.
---- ---- ---- ---- ---- ---- ----
IT'S 100% SOFTWARE. SAME FILER. SMARTER COMPUTE FARM.
When we first set up our GDP data management customers such as AMD, Maxim,
Nvidia, Samsung, and Xilinx, they *all* told us that working with their
existing file-based system and compute farms was mandatory.
Neither their CAD teams nor their IT teams were willing to disrupt their
existing production chip design and verification flows.
PeerCache is 100% software, and will plug-and-play into your existing file
systems and compute farms. The devil is in the details:
- Compute Farms. PeerCache takes your existing compute farm and
gives you smart grid computing by sharing the flash storage.
(e.g. LSF, Sun Grid, RTDA NC)
- Filers. With PeerCache your authoritative data is still saved to
your filer, preserving your existing reliability, uptime, backup
and disaster recovery. (e.g. NetApp, Isilon ...)
- Cloud. While most of the larger chip design companies are not yet
ready to trust their data in the cloud, PeerCache will work with
those who do by offering cloud bursting and cloud caching.
(e.g. Amazon AWS and Microsoft Azure)
- EDA Tools. There is no need for customization here. PeerCache just
works with all of them since it presents a regular file system
interface. Some examples are: RTL simulation regressions, timing
analysis, power/IR/EM tools, physical synthesis, P&R, and layout.
To make PeerCache work in your environment, you install at least one server
called the Tracker and run a daemon on each compute node. The servers are
a fully distributed, tracker-directed peering architecture that is highly
fault tolerant.
---- ---- ---- ---- ---- ---- ----
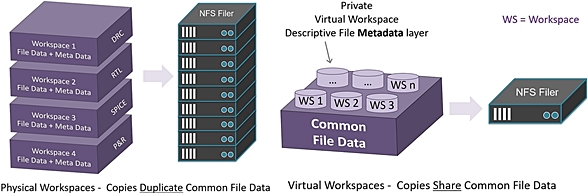
VIRTUAL WORKSPACES = 1/10TH OF THE FILER DISK STORAGE USE
PeerCache uses virtual workspaces, which require much less disk storage than
multiple physical copies do. To do this, we separate your file data into
two layers:
- Descriptive file metadata (file name, size, owner, group,
mask, create/access/modify time...)
- File content (all the actual bytes your EDA tools needs...)
I covered the details of this mechanism in my 2016 PeerCache article. Also,
Broadcom discussed the advantages of virtual copies over physical copies for
our earlier IC Manage Views product which worked on managed data. With
PeerCache, you get virtual workspaces for both your managed and unmanaged
data.
With virtual workspaces, you can immediately access your work files -- we
call this "zero-time sync". Making copies takes only seconds or minutes,
vs. before it took hours.
Why virtual workspaces save your disk space:
1. We only transfer the files that are actually accessed. We treat
this as an LRU cache to minimize hardware resources, so that only
small flash volumes are required.
2. When you create multiple new workspaces, you avoid duplication.
This is because we make one metadata copy but point to the same
set of common files, so that all the workspaces on a given host
share the same common files.
Thus, by using virtual workspaces, you can cut your NFS filer storage
usage to only 1/10th. This is because all duplication is in the caches,
and not in the NFS filer's authoritative data.
- Your core design is an invariant copy that doesn't change.
- Only your metadata changes, and per-workspace changes require
additional storage. Once those changes are checked in, the space
is automatically freed up.
On the left is the old school way of making multiple full copies of your
full chip to do some operation (like DRC, or SPICE, or PnR). Notice that
it's a filer hog with all those many duplicate copies of your full chip.
On the right is the PeerCache virtual workspace that only has one metadata
layer and lots of much smaller virtual workspaces -- a 9X reduction in filer
space needed!
PeerCache not only does all this for your managed data, it also does it for
the other 90% (which is your unmanaged data.)
I discuss that unmanaged data next.
---- ---- ---- ---- ---- ---- ----
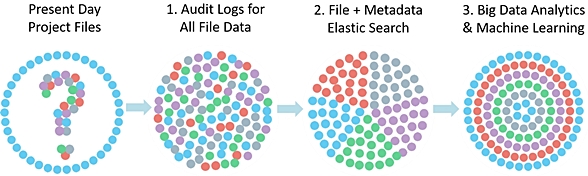
NEW: NOW ALL DATA GETS AUDIT LOGGING & BIG DATA ANALYTICS
Everyone painfully shares the unmanaged project data -- it's one mega tree
from hell with manual revision copies such as 1.0, 1.1, 2.0, 2.1, etc. This
unmanaged data (such as physical design and simulation data) causes major
problems. Above I discussed how PeerCache fixes the NFS I/O and storage
bottleneck problems.
Now I'll discuss new stuff like design status and security issues.
1. Audit Logs - with File Data and File Metadata
What companies do today:
- Design and verification teams today do not know what's
happening with all their files, because NFS is block-based
and it has no capability for file logging.
- Some of the larger chip design companies do explicit log file
gathering at the EDA tool use level.
- Some companies do endpoint monitoring for security purposes,
using tools such as Digital Guardian. (I will discuss in more
detail in section #3 on analytics.)
With PeerCache:
- Detailed information is automatically logged as part of the
meta-data translation described in the virtual workspace
section above. Audit logs are generated for all operations
on every file.
- There is an analytics plugin that allows you to connect the
log data to any backend analysis, as discussed in more detail
below. Development teams can now finally automatically access
all their design and verification history, such as how many
times DRC was done or a specified tool run was on a specific
block.
- PeerCache also has built-in data anonymization. Various local
laws required separation of the analytics data from the
individual users; the data-user link is only accessed if
certain protocols are complied with.
2. Search queries on prior file actions.
What companies do today:
- Because there is no (or limited) project log data, or only
collected semi-manually, most file-based searches are rarely
done today -- other than endpoint monitoring for security
purposes I mentioned above.
With PeerCache:
- Because all log data is now automatically collected (even for
that 90% of data that is unmanaged) companies can finally
do meaningful deep analytics.
- PeerCache interfaces to Elasticsearch, an open source search
and analytics engine, to open the file system. Using Elastic-
search, you can do fast search queries on your large volume of
log data. You can see exactly what changes were made to
every file -- again, even for your derived/ unmanaged data.
Once an interesting detail is discovered, you can zoom in
to explore it in detail.
- If there is an attempted theft or cyber-attack, the file
system access can be immediately revoked. You can see how
and when files were accessed, modified, stat'd, renamed or
deleted.
3. Big Data Analytics and Machine Learning
What companies do today:
- Some of the larger companies have invested in custom in-house
solutions to analyze their data.
- Data Loss Prevention: Other companies have the endpoint
monitoring security analytics I mentioned earlier. However,
when there is a successful attack it's difficult for them to
isolate where the point of infiltration was initiated, and
stop it without impacting production -- so the data can
continue to leak.
With PeerCache:
- You can use the information obtained from your Elasticsearch
to create graphs to analyze points of interest. Folding
activity data over a single day and clustering by location
can show how work flows over the globe daily.
- You can link the data to the IC Manage Envision Big Data
Analytics dashboard for design progress analytics and tapeout
prediction based on the work activity generated by a project
over time.
- Your data is also available to any other big data analytics
tools you may have.
- Data Loss Prevention: PeerCache provides machine learning
analytics to prevent IP theft.
- You can filter activity by cluster, and then set rules
for flags, real-time alerts, and revoking of permission.
- You can actually prevent the theft, rather than finding
out after the fact.
The result of these mechanisms is that you get actionable information from
what used to be the project mega tree from hell.
---- ---- ---- ---- ---- ---- ----
FLASH STORAGE: NVMe VS. SSD
The NVMe standard for flash storage is growing in popularity worldwide.
Most smartphones and laptops already have it. NVMe is a communications
protocol that takes advantage of pipeline-rich random access memory-based
storage. Some of NVMe's most significant advances are:
- NVMe can simultaneously process up to 65,536 queues.
- SATA SSDs can only process 1 queue at a time.
- SSD uses the Linux Advanced Host Controller Interface (AHCI) which
was designed for hard drives back in 2004. AHCI requires four
uncachable register-reads-per-command, which results in 2.5
microseconds of additional latency, compared with NVMe, which does
not require any register-reads to issue a command.
---- ---- ---- ---- ---- ---- ----
Systems and semiconductor companies have traditionally "scaled up" with more
NFS filer storage. The horizontal compute farm "scale out" that PeerCache
offers is already available in places like as Google, Amazon, and Facebook.
Chip design and verification engineers are always pushing for more SPEED.
Leveraging NVMe caching using P2P to a create smart networking of their
compute node "silos" can deliver that speed fast, with security, while
reducing NFS filer storage costs.
- Shiv Sikand
IC Manage, Inc. Campbell, CA
---- ---- ---- ---- ---- ---- ----
Related Articles
IC Manage PeerCache and CDNS Rocketick get #3 as Best of 2016
Shiv on ICM's PeerCache secure BitTorrent-style workspace tool
524 engineer survey says network bottlenecks slow EDA tools 30%
Join
Index
Next->Item
|
|