( ESNUG 574 Item 3 ) -------------------------------------------- [06/13/17]
Subject: Jean-Marie warns Synopsys Zebu needs 9X more "warm bodies" to run
The Palladium Z1 has 2 options -- 384M gates and 576M gates. So let's be
nice to our competitor, we will give them the 576M gate option. So to do
2.5B gate you will need at least 4 boxes. (With the 385M gate you will
need 6 boxes.)
In both cases, the combined floor footprint is larger than Strato. So no
datacenter foot^2 floor use advantage with a rack-based approach.
In terms of power, our data shows that for 4 to 6 Palladium Z1 boxes will
consume 250 Kw to 300 Kw -- about 5x to 6x more power than our Strato (with
Strato being at 50 Kw). Palladium Z1's need water cooling for both the 384M
and 576M gate option. Our Veloce Strato is eco-friendly and does not require
water. Our customers love the fact that Veloce's don't need water cooling.
- A surly Jean-Marie sasses Cadence Palladium and Synopsys EVE Zebu
From: [ Jean-Marie Brunet of Mentor ]
Hi, John,
Several months ago DeepChip ran a letter where I compared Mentor's Veloce
Strato platform, to Cadence's Palladium Z1 and Synopsys' Zebu 3. To add to
that write up, I'd like to open a discussion on the cost of support for an
emulator.
In today's sales environment, it's common to see Synopsys trying to sell
their Zebu Server for roughly $100,000 less than the equivalent Veloce box.
On the surface that looks like a pretty good deal.
But when a customer goes with Synopsys and begins to use their system, some
months later they learn (too late) that they would have been better off with
a Veloce. Why? One reason is Rent's Rule (see explanation below), but the
more tangible argument is based on actual Cost of Support. Here's how
saving $100K on emulation HW ends up costing you up to $1,350K in support.
---- ---- ---- ---- ---- ---- ----
RENT'S RULE
Early emulation used commercial FPGAs as their CPU (like the ZeBu today.)
They were cheap and FPGA throughput was blazingly fast. The problem was
mapping your chip into the Xilinx LUTs could easily take months!
And as designs got bigger, the mapping problem grew exponentially worst for
the Zebu boxes. Frank wrote about this in ESNUG 532 #2.
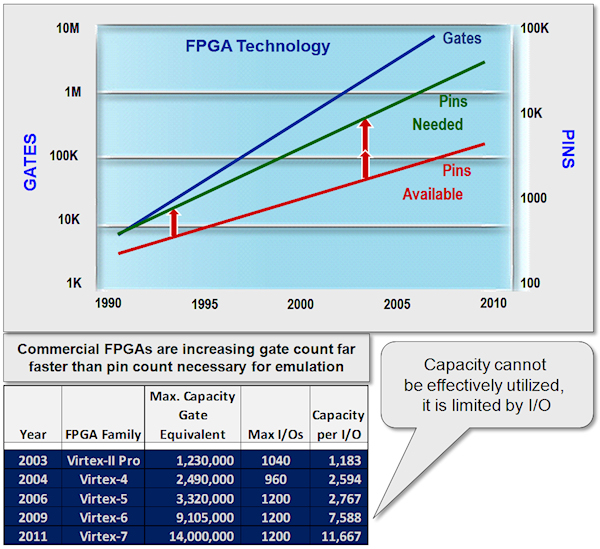
It's called Rent's Rule, where the larger an FPGA gets, the more it will run
out of pins long before all its available DUT capacity is utilized. Here's
the graphic Frank used:
Fig 1: Rent's Rule -- Interconnect between FPGAs gets more difficult
(Click on pic to enlarge.)
To cope with the Rent's Rule bottleneck several interconnection schemes were
devised over time:
- interconnect from nearest neighbor,
- full crossbar,
- partial crossbars,
- and then synchronous and asynchronous time pin multiplexing.
None of these schemes eliminated the problem for long. So the Mentor Veloce
and Cadence Palladium R&D teams abandoned commercial FPGAs and replaced them
with their own proprietary CPUs implementing custom emulation architectures.
These custom CPUs fixed the Rent's Rule bottleneck.
---- ---- ---- ---- ---- ---- ----
"INVISIBLE" EMULATOR SUPPORT COSTS
One factor that is often "invisible" during the purchase decision is the
added engineering cost of support "warm bodies." Because each time you
when want to use the FPGA-based Zebu emulator, there's this rather long
time-consuming, cumbersome, and frustrating task of mapping your design
onto the Zebu system. (For example, a small 256MG design maps onto 5 Zebu
boards, with each board holding nine Xilinx Virtex-7 XC7V2000T -- this
makes 45 FPGAs that you must first partition and then map your 256MG
design into.)
Add in the real-life complex clocking, power switching, and scan testing
schemes to complicate things, and this Zebu FPGA partitioning/mapping task
often takes several full calendar months to do for a large chip.
It is never under a week for even the smallest design.
So what's the SNPS Zebu team to do?
Compensate by committing an army of engineers, partly Zebu R&D personnel and
partly Zebu field application engineers. They provide on-site support, work
side by side with customer design engineers, and assure that the customer's
designs are ready for emulation (often after few calendar months.)
So let's assume 1 engineer costs $150K per year.
MENT SNPS
Veloce Zebu
------------ ------------
on site vendor FAEs: 1 engrs 4 to 5 engrs
on call vendor R&D: 0 1 engrs
customer chip designers: 0 2 to 3 engrs
------------ ------------
added engineering costs: $150K $900K to $1,350K
Suddenly that $100K "cheaper" ZeBu Server 3 configuration actually costs the
Synopsys Zebu customer from $900K to $1,350K more per year per because of
these unstated engineering "warm body" expenses.
As a rule of thumb, a SNPS Zebu configuration needs 7X to 9X more technical
support engineers than the equivalent Veloce configuration.
So if your company is working on 10 chips and you're using Zebu, expect to
see ~100 engineers coming and going to support the Zebu boxes. And if your
chips are larger than 256 million gates, expect the added Zebu support staff
to grow even more. But instead, if you went Veloce, you'd see only one or
two FAEs on occasion.
This is because Veloce's "light touch", the user just loads up his or her
chip into the emulator, hits compile, and an hour later it's running in the
machine. (In truth, MENT has made their compiles to be painless, so that a
Veloce FAE is rarely needed, but I had to list at least 1 for comparision
purposes.)
The Zebu approach is "deep touch", where there's an army of Zebu support
staff -- plus the customer's own design engineers tearing things apart to
map their chip into ~100 Virtex-7's over a month or two.
---- ---- ---- ---- ---- ---- ----
A DANGEROUS SYNOPSYS DEPENDENCY:
Even if the 9X higher support costs wasn't a factor, it may seem as long as
the commitment is shouldered by the SNPS Zebu staff, the Zebu customer may
enjoy the benefits without penalties. This is a wrong perception.
Being so dependent on one supplier is worrisome for three reasons:
1. Requiring involvement of your own lead chip design engineers (scarce
resources in any IC design organization) for the design bring-up in
the Zebu emulator is a proposition few companies can afford. Your
chip design folks have other more pressing problems to deal with
instead of trying to get their chip into a Zebu Server 3 box.
2. The sheer volume of engineers required for deploying a Zebu, even if
they are available for hire, is prohibative. These are not just
cheap college newhires you can have do this; mapping a 500 million
gate ASIC SoC into ~90 Virtex-7's takes engineers who know Verilog
RTL coding, synthesis, ASIC gates, Xilinx LUTS, and how to deal with
complex CDC/power/scan issues, too. These are expensive engineers
to hire!
3. Any customer company that must rely on a emulator vendor's army of
engineers for a mission critical task gives that emulator vendor
dangerously excessive leverage that could be reduced at any time.
What guarantee do you have that the Synopsys support staff is truly
'committed' to the 1000's of man-hours needed to complete your chip?
Vulnerability, especially when that 'control' is in someone else's
hands, inserts unpredictability into what needs to be a predictable
process.
Your company needs to rely only on its own engineers to run the emulator
that they bought. That means setting up and training your own internal
support organization. With Veloce being "light touch", this is easy to do.
With Zebu being "deep touch", and its inherent Rent's Rule problems, it
forces you to be dependant on a small army of Synopsys Zebu employees.
Do you have an extra $1,350,000 to pay for the requisite Zebu support?
- Jean-Marie Brunet
Mentor Graphics Corp. Fremont, CA
---- ---- ---- ---- ---- ---- ----
Related Articles:
A surly Jean-Marie sasses Cadence Palladium and Synopsys EVE Zebu
SCOOP -- will the new MENT Veloce Crystal 3 chip crush Palladium?
Hogan compares Palladium, Veloce, EVE ZeBu, Aldec, Bluespec, Dini
Frank - Lauro missed Veloce2 and Zebu lame gate ultilization
Join
Index
Next->Item
|
|