( ESNUG 588 Item 13 ) --------------------------------------------- [02/07/20]
Subject: 2nd Fusion Compiler vs. CDNS 19.1 benchmark plus 3 CDNS 19.1 bugs
We've just swiched over to Genus/Innovus/Tempus 19.1 and here's how we
made it work. First, here's the four new parts of the new CDNS 19.1 flow
in a nutshell.
- new physical restructuring with iSpatial
- new Mux and Datapath Restructuring
- new Machine Learning based optimization
- new Tempus ECO that skips post-route optimization
Cadence believes in common engines. They used to have common *placement*
and common *routing* engines across all the tools. With CDNS 19.1, we
get their "iSpatial", which what Cadence marketing calls putting GigaOpt
everywhere in their flow to have one common *optimization* engine
everywhere, too. (GigaOpt is the optimization engine orginally in their
Innovus. Now it's in Genus and Tempus, too.)
With iSpatial we see a ~1.8x runtime speed up for our full 19.1 flow vs.
the old 18.1 full flow. The new iSpatial predicted our area exactly, and
our power exactly (because it's GigaOpt moved upstream into Genus). This
better timing used by our RTL team to tune the RTL. So when this better
19.1 data is taken to Innovus, Innovus doesn't have to do placement
optimization again. Innovus 19.1 goes purely incremental after that,
which is what gets us that 1.8x runtime speed up.
To enable iSpatial we needed to do the following switches:
set_db limited_access_feature {ispatial 214480224}
set_db opt_spatial_effort extreme
syn_opt -spatial
This is what we're using now because it's what the Cadence folks told us
to do. Are other users using different switches to turn on iSpatial?
- from 12 good and 4 bad switches in new Cadence 19.1 flow
From: [ Jumanji, the Next Level ]
Hi John,
Please keep me anonymous on this.
Thanks a lot for the Cadence 19.1 flow write-up and the 12 good and 4 bad
switches to look for.
The way things have turned out for us, we are having to move extremely fast
down the foundry process nodes. We do a lot of different chips in a year,
and up until now we had one node for at least a year or two (below 10nm).
Now we seem to be changing nodes often given the various markets our chips
have to be targeted to. A few for mobile, a few for automotive, a few for
ML applications etc.
Traditional chip design wisdom requires us to *only* change one thing at a
time out of these three:
- only change our chip architecture,
- only change our foundry node, or
- only change EDA tools.
A perfect storm for us -- pretty brave of us -- or pretty stupid of us -- is
when we change all three things at the same time.
For the longest time we have used both Cadence and Synopsys tool sets. Our
procurement works by getting a few things from both these EDA vendors. For
last 2-3 years I should say we have been mostly (80%) Cadence Innovus flow
in the backend, and (30%) Genus flow for high end CPU design and (40%)
Tempus sign-off for very large chips. I think this aligns with how many
people have been using Cadence for last 2-3 years.
For Synopsys we have been mostly (70%) Design Compiler, backend very little
(20%) ICC2, and (70%) Primetime for our smaller chips.
This benchmark is to see how the full flow Synopsys Fusion Compiler measures
up against Cadence 19.1 Genus/Innovus/Tempus.
Our problem zone has been time-to-results (TTR) for synthesis flows. The
block sizes used to be 400 K to 2.0 M instances. But we are forced to up
the block sizes to 1.2 M - 4.0 M given the content in the chips is becoming
bigger and our schedules are shrinking. This increase in block size has
essentially choked our DC-Graphical runtimes. Our old flow was
DC-Graphical -> Innovus/Tempus --> PT for golden signoff
which does the whole physical synthesis. It has done well hitting our power
goals, but we're worried about increasing block sizes and backend flow
runtimes.
Our signoff goal has been to increase our number of signoff corners. We
went from 84 corners in our previous node to 137 corners in the present
node. (Sorry I can't be specific about our nodes, but it'll give us away.)
Every block has to be signed-off in all those corners and the top level has
to be signed-off across those.
And with multiple chips going in parallel our compute requirements are off
the charts for us to get signoff done just for STA. Add in IR-drop and test
and DRC checks on top of this and it's a compute farm/cloud using nightmare.
This is not something we can just keep buying infinite hardware and/or cloud
time for.
We know Tempus supports concurrent MMMC, but we haven't tried it yet. We
normally just use PrimeTime one corner at a time.
So our four concerns are:
- block sizes and synthesis runtime
- block sizes and PnR runtime
- who has better QoR?
- our signoff hardware/cloud use requirements
We started this benchmark back in May 2019. We have 5 blocks (each with
their own unique problem) that we've taken from prior chips.
Name Design What It's Testing
------- ------------ ----------------------------------------
Block A ARM CPU fasted clock frequency
Block B 5G Modem smallest floorplan Catapult SystemC RTL
Block C GPU Shader lowest mW total power
Block D Image Sensor uP smallest floorplan on stable Verilog RTL
Block E Arteris NoC least DRC errors
---- ---- ---- ---- ---- ---- ----
SNPS DC-GRAPHICAL vs. CDNS GENUS synthesis with Innovus PnR
|
Block
|
Best
Synthesis
Runtime
|
Innovus
Runtime
|
Block A
ARM CPU
|
Genus:
0.6 days
|
4.2 days
|
Block B
5G Modem
|
DC-Graphical:
3.1 days
|
3.7 days
|
Block C
GPU Shader
|
DC-Graphical:
4.7 days
|
4.9 days
|
Block D
Image Sensor uP
|
DC-Graphical:
2.2 days
|
3.3 days
|
Block E
Arteris NoC
|
Genus:
0.6 days
|
5.1 days
|
Table 1: Evaluation blocks and best-known synthesis + Innovus runtimes
We needed to cut down our total runtime by at least 30%, and move the whole
flow to handle more corners. Our runs were single corner in synthesis and
4 corners in PnR. We need to move this to 4 corners in synthesis and
8 corners in P&R to make sure our sign-off is a little easier.
We invited both Synopsys with their Fusion Compiler and Cadence with their
latest 19.1 offerings. Both companies of course claimed a lot on how they
can help us. Our goal was nearly single flow/tool for all of our blocks.
And that we need to have the whole thing running on our network using our
engineers. This is a must. 5 years back we had to get Synopsys to have
their AEs own our tape-out because we trusted their slides. This did not
go well with our management.
The first thing we noticed is Fusion Compiler requires us to re-code all
our front-end infrastructure to the new language -- Tcl with new commands
and new attributes thrown in. It's not backwards compatible with DC-Topo
nor DC-Graphical. A bit of a downer, but if the QoR was much better we
could take that up. The CDNS Genus flow we had is same scripting language
for CDNS Innovus 19.1, too. But we needed to see Genus scale for the other
blocks, too. It was proven before in our old benchmarks that for CPU design
Genus/Innovus was the best flow. But is it better for other design styles?
---- ---- ---- ---- ---- ---- ----
FUSION COMPILER IN TAXICAB MODE
Our Synopsys support team insisted they run all of our blocks (taxicab mode)
and give us the results.
Old wounds from 5 years were getting re-opened. After 3-4 months of work
and regular updates, these are best known results we have seen. Synopsys
says they are continuing to improve results but our benchmark is ending
now after 6 months of effort.
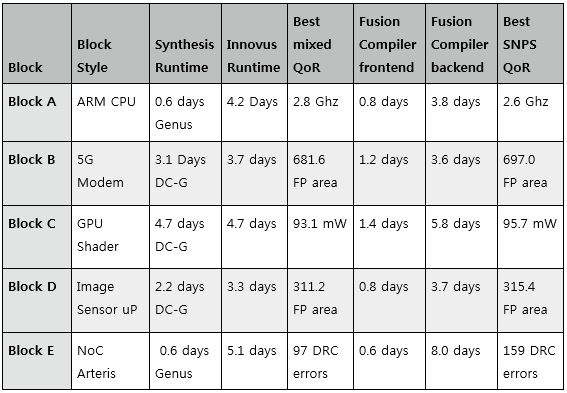
Table 2: Best mixed-tools vs. and all Fusion Compiler results
Conclusions for DC-Graphical vs. all Fusion Compiler benchmark
A. Good synthesis runtime improvement. The Fusion Compiler frontend
synthesis runtimes averaged 3x faster than DC-Graphical synthesis.
B. The Fusion Compiler backend runtimes are roughly same as Innovus.
This is a bit of concern because Innovus is starting from a fresh
placement on every run while Fusion Compiler is supposed to have
a handoff, in which they take the placement from synthesis and
run incremental. But the runtime benefits are not evident to us.
Maybe because its spending time to crunch down QoR?
C. On the easiest of the blocks - Image Sensor uP - we are able to
see that Fusion Compiler can give us 20% runtime improvement with
QoR being unchanged.
D. Fusion Compiler has difficulty in shrinking area-sensitive blocks.
The key metric on our modem blocks is area and it didn't converge
when we push utilization. It's also evident from our Arteris NoC
blocks -- the runtime to converge to a reasonable DRC error count
is large. We are worried with this. We need to get the best
metrics on costs for our die size given our volumes.
E. We are able to do more MMMC corners in Fusion Compiler synthesis
and PnR now, but if we lose QoR in the process, this is a no go
for us. We don't ship the corners. We ship our QoR.
NO FUSION COMPILER FRONTEND DATA TO INNOVUS INPUT IS ALLOWED
We asked our Synopsys support to get us the Fusion Compiler frontend
netlist to feed to our established Innovus PnR flow. This was denied.
Absolutely no Fusion Compiler frontend netlist can go to the Innovus
backend. This is a red flag. My personal opinion is that a closed
system is never a good idea. We would like to use our backend with
any frontend tool we choose.
---- ---- ---- ---- ---- ---- ----
FUSION COMPILER vs. ALL CADENCE 19.1 FLOW BENCHMARK
Moving on to Cadence. They gave us the 19.1 flow with a few things that
were mentioned in the ESNUG 587 #5 post. iSpatial was their big claim,
along with their Compus logic & datapath flattener. The Cadence FAE's
worked on these 5 blocks for 3 months with us participating, getting regular
updates from the support team and us running the flows ourselves. We agreed
to a monthly delivery of Cadence R&D scripts that we would be able to run
and experiment on ourselves. This was a good working relationship for us.
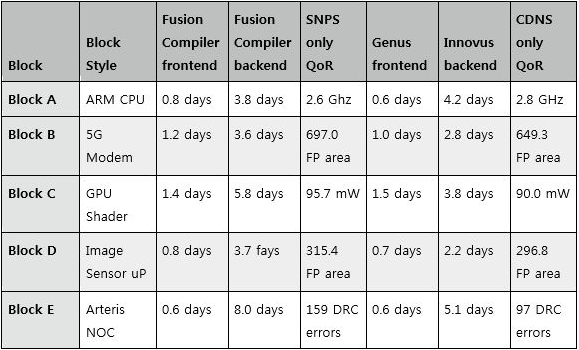
Table 3: Fusion Compiler vs an all Cadence 19.1 results
Conclusions for an all Cadence 19.1 vs. all Fusion Compiler benchmark
A. We didn't have to change our frontend scripts to get to Cadence 19.1
B. For frequency results, with Block A, the Cadence 19.1 runtime total was
4.8 hours slower than Fusion Compiler - but it got a 200 MHz boost to
our frequency.
C. Our Catapult SystemC 5G Modem (Block B) got a 1.3x faster with an
excellent 6.8% shrink of the floorplan for the modem. This really was
the highlight I would say. We haven't seen that kind of area before.
D. The handoff from Genus into Innovus works nicely because of the Innovus
runtime shrinks. Also there seems to be additional runtime benefit
just in 19.1 by itself, too.
E. We have 65 to 70 new switches to integrate in our flow. It's probably
manageable since we got monthly flow drops from Cadence that we could
integrate. But they need to document these!
NO GENUS NETLIST TO FUSION COMPILER BACKEND ALLOWED, EITHER!
We asked the same questions to Cadence support. If we could take the CDNS
Genus netlist into SNPS Fusion Compiler backend. They agreed and laughed
and told us it won't work, but you can try it. It was due to handing off
skew metrics, layer promotions, etc. that we never could make it work. No
way to get all that information into Fusion Compiler. So this activity
stopped immediately. But for us, Cadence agreed to an open system.
---- ---- ---- ---- ---- ---- ----
CADENCE 19.1 ISSUES
We did find our share of issues with the Cadence 19.1 flow.
1. One thing I can share with users is the whole flow around secondary power
grid routing. Now in every high end chip I know of there are secondary
power grids that have to be routed to the cell pins. This is a very
resistance sensitive signal. I am sure everybody has it.
The Cadence 19.1 method that was in our flow was based on their Nanoroute
engine. It takes the same routing approach as signal nets for these
IR drop critical nets. It creates zig-zag routing, detours and connects
multiple pins from a single source. Nobody in the right mind would do
that. Because the resistance at these technologies kills you and the
IR drop on those nets is way too high.
The workaround we used to get around this was:
setPGPinUseSignalkRoute instLpin
routePGPinUseSignalRoute -net -fanout
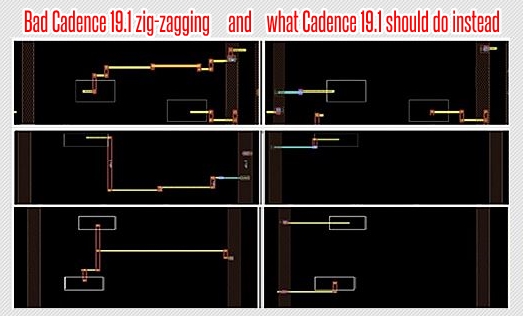
This is just plain bad and we have let Cadence know. I have a pic with
the bad routes on the left above and what our engineers drew manually.
If you look at the pic on the left which Cadence did, the routes are
too resistive. What we ideally want is the routes on the right with
our manual approach.
Cadence says they can get there, but we are waiting. They told us about
this option:
addStripe -nets -layer -width -spacing -connect_secondary_pins
but we haven't tried it yet. I am seeing if anybody has tried it and to
hear their experience with this mesh based secondary PG pin routing.
2. The Cadence 19.1 flow lacks a proper glitch power optimization flow.
There are three components to power reduction.
a. Architecture of the chip advancements with IEEE 1801 power intent
is the first big factor.
b. The second one is node transitions. As the industry transitions
to 3nm the process node brings down power consumption.
c. The third is tool capabilities to reduce power.
While CDNS 19.1 can do power optimization for leakage and dynamic power,
we are finding that 30% of our power now is glitch power. We have no
flow in Cadence 19.1 to optimize glitch power. We need ability to gate
glitching circuits and to balance delays on buses to optimize the glitch
power. Even if Cadence can half our glitch power, we would get 15%
power savings.
3. Cadence 19.1 ends up with slightly higher "hold" violations due to its
aggressive scan chain reordering. The wirelength reduction we get with
scan chain reordering is very nice. But those small wires have much
less resistance and capacitance. This is good for congestion, but not
good for hold. The proper solution to this is to be "hold" time aware.
If a slightly longer scan length can reduce "hold" violations we need
that. Burning power on those extra "hold" buffers is not what we want.
Please fix that.
---- ---- ---- ---- ---- ---- ----
OUR CONCLUSIONS FOR BOTH CADENCE & SYNOPSYS
In summary, we've found that the Cadence 19.1 full flow has better PPA
and TTR than the present Synopsys Fusion Compiler flow. More importantly
we get faster chips with lower power and smaller die sizes with it.
We would be standardizing to an only Cadence 19.1 flow, but we will keep
some Fusion Compiler around for a handful of our easy partitions just to
keep Cadence honest.
Scope for improvement for Cadence: Please document the new switches and
its use model. I am hoping by the time we tape-out we have to have them
documented and maybe CDNS R&D reduces the number of switches. And yes,
productize the secondary PG pin routing solution. And optimize glitch
power consumption. And fix the "hold" violation on scan chains issues.
Scope for improvement for Synopsys: Please create an open system, and work
on improving your QOR. Just a faster synthesis tool is not enough.
I will write later about how we are handling the hardware challenge. Too
busy now!
- [ Jumanji, the Next Level ]
---- ---- ---- ---- ---- ---- ----
Related Articles:
12 good and 4 bad switches in new Genus/Innovus/Tempus 19.1 flow
User benchmarks DC-ICC2 vs Fusion Compiler vs Genus-Innovus flows
Genus RTL synthesis gaining traction vs. DC is #4 of Best of 2017
After 16nm benchmark, 7nm user swaps out DC-Graphical for Genus-RTL
ICC2 patch rev, Innovus penetration, and the 10nm layout problem
Aart's SUE RIVALS policy backfires horribly on core SNPS patents
Join
Index
Next->Item
|
|